Several sites offer Fantasy Premier League lineup predictions, useful information for making your gameweek plans. The problem is that none of them (publicly) revisit those predictions to say how they did, and it’s impossible to improve your predictions without measuring their success. I wanted to build something to do that, and hopefully create some competition between the sites. Here is the finished result – or at least, the MVP:
I built an (almost) entirely automated system to read predictions in from several sources, calculate the errors, and publish them on Twitter each gameweek. I wrote it in Python and SQL, using Selenium, Pandas, NumPy, Tesseract OCR, and Tweepy.
Input
The postgreSQL database contains master tables of teams and players, spelling tables for both, fixtures, predictions, and then confirmed team lineups. I used Selenium to grab the text I need from each site, process it in Python, then add it to those tables.
The first problem was that sites use different spellings or formats for the same players, for example:
GABRIEL MAGALHÃES
GABRIEL MAGALHAES
Gabriel M.
Gabriel
In this example, my master table of players has Gabriel from Arsenal. Then there is a table of alternate spellings that refers back to that master list. Whenever the program comes across a player spelling that it hasn’t seen before, it asks for human confirmation of who it is from the master list. That made for quite slow going at the start, but now it needs one or two confirmations for each gameweek of >200 players.
The Guardian show their lineup predictions as images. I can read the image in with the same kind of methods as for the other sites, except with the major advantage of being able to read the archive rather than just the predictions for this week. The major disadvantage is that they often miss games, they vary their url scheme, they run several adverts I need to click away, and they sometimes misspell player or team (!) names. The code to input Guardian predictions is as long as that to input all other sites combined.
Once I have the image, I need to perform OCR on it, which I do using Tesseract. The first step is to pre-process the image, to make it easier for the ML model to read:
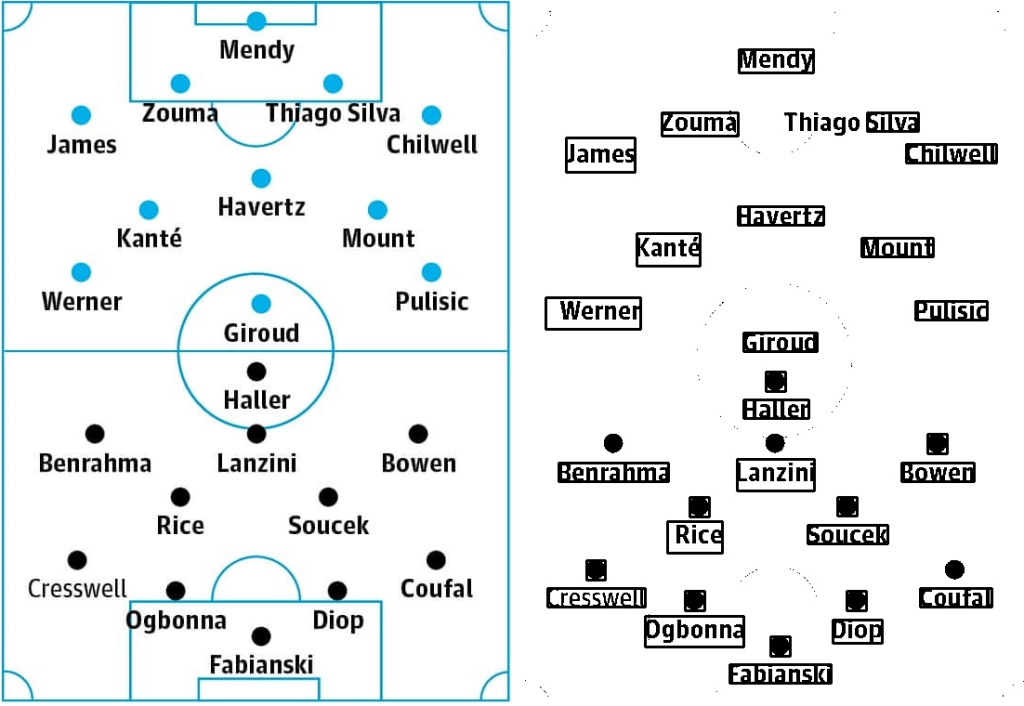
The model then returns a list of words that it finds in each box, which can then be inserted to the predictions table as normal. The model gets about 9/10 names right, and has particular problems with ones like “Thiago Silva”, so there’s some human editing required here too. Once all this worked, it was just a matter of crawling through all Guardian football stories this season, looking for match previews.
Analysis
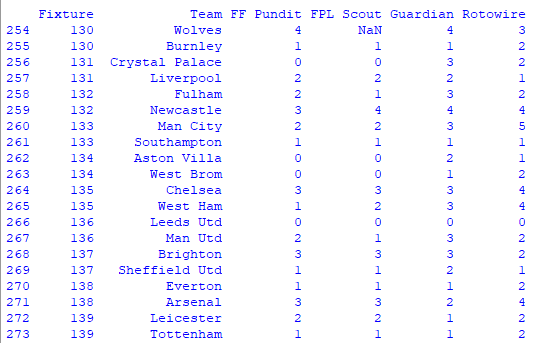
Once I have the confirmed lineups, I check the most recent prediction from each site for that game. This is where Pandas and NumPy come in. Below is last Game Week’s error counts, using a Pandas dataframe:
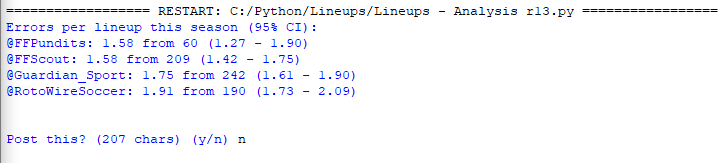
I can then automatically calculate errors per site, gameweek, or team, and automatically post them to Twitter using Tweepy:

Next
- Best & worst predictions of the past week
- Various code improvements
- Add https://www.sportsmole.co.uk/football/spurs/predicted-lineups/
- Add https://www.telegraph.co.uk/betting/football/
- Add https://www.teamfeed.co.uk/lineups/competition/england/premier-league
- Add The Sun (OCR) predicted lineups
